
Debating in class or composing a persuasive paper is a fruitful intellectual practice. Doing so, participants and writers are expected...
Read More
February 28, 2024
Generative Adversarial Networks (GAN) are a relatively new concept in Machine Learning, introduced for the first time in 2014. Their goal is to synthesize artificial samples, such as images, that are indistinguishable from authentic images. A common example of a GAN application is to generate artificial face images by learning from a dataset of celebrity faces. While GAN images became more realistic over time, one of their main challenges is controlling their output, i.e. changing specific features such pose, face shape and hair style in an image of a face.
A new paper by NVIDIA, A Style-Based Generator Architecture for GANs (StyleGAN), presents a novel model which addresses this challenge. StyleGAN generates the artificial image gradually, starting from a very low resolution and continuing to a high resolution (1024×1024). By modifying the input of each level separately, it controls the visual features that are expressed in that level, from coarse features (pose, face shape) to fine details (hair color), without affecting other levels.
This technique not only allows for a better understanding of the generated output, but also produces state-of-the-art results – high-res images that look more authentic than previously generated images.
The basic components of every GAN are two neural networks – a generator that synthesizes new samples from scratch, and a discriminator that takes samples from both the training data and the generator’s output and predicts if they are “real” or “fake”.
The generator input is a random vector (noise) and therefore its initial output is also noise. Over time, as it receives feedback from the discriminator, it learns to synthesize more “realistic” images. The discriminator also improves over time by comparing generated samples with real samples, making it harder for the generator to deceive it.
Researchers had trouble generating high-quality large images (e.g. 1024×1024) until 2018, when NVIDIA first tackles the challenge with ProGAN. The key innovation of ProGAN is the progressive training – it starts by training the generator and the discriminator with a very low resolution image (e.g. 4×4) and adds a higher resolution layer every time.
This technique first creates the foundation of the image by learning the base features which appear even in a low-resolution image, and learns more and more details over time as the resolution increases. Training the low-resolution images is not only easier and faster, it also helps in training the higher levels, and as a result, total training is also faster.
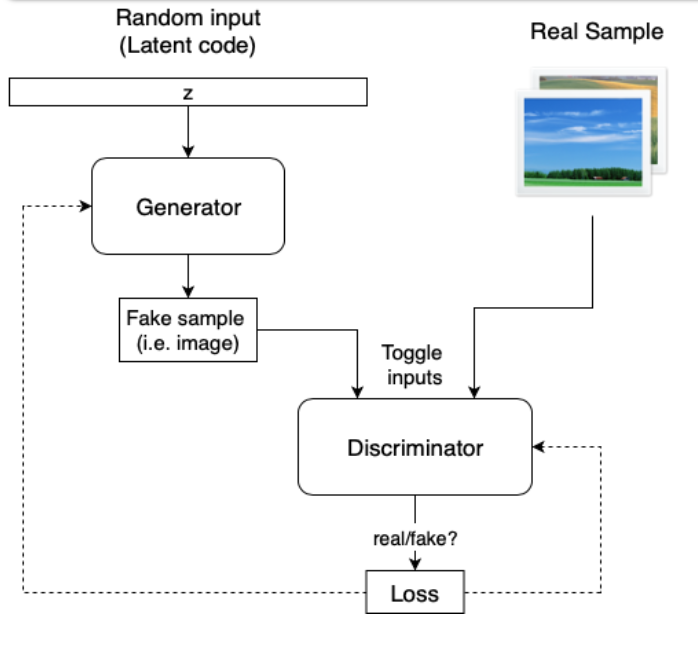
ProGAN generates high-quality images but, as in most models, its ability to control specific features of the generated image is very limited. In other words, the features are entangled and therefore attempting to tweak the input, even a bit, usually affects multiple features at the same time. A good analogy for that would be genes, in which changing a single gene might affect multiple traits.

The StyleGAN paper offers an upgraded version of ProGAN’s image generator, with a focus on the generator network. The authors observe that a potential benefit of the ProGAN progressive layers is their ability to control different visual features of the image, if utilized properly. The lower the layer (and the resolution), the coarser the features it affects. The paper divides the features into three types:
The new generator includes several additions to the ProGAN’s generators:
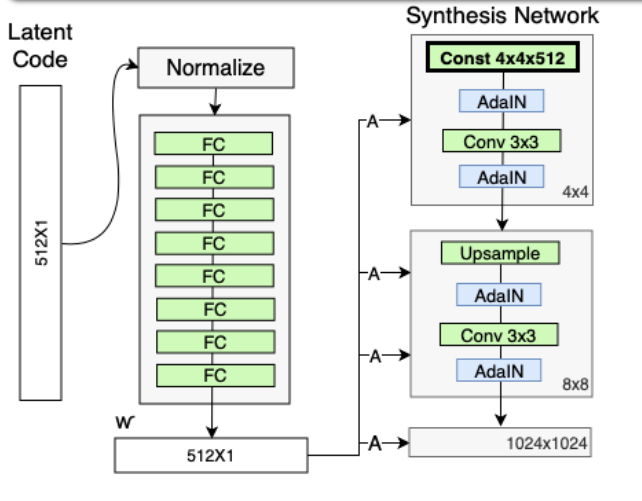
The Mapping Network’s goal is to encode the input vector into an intermediate vector whose different elements control different visual features. This is a non-trivial process since the ability to control visual features with the input vector is limited, as it must follow the probability density of the training data. For example, if images of people with black hair are more common in the dataset, then more input values will be mapped to that feature. As a result, the model isn’t capable of mapping parts of the input (elements in the vector) to features, a phenomenon called features entanglement. However, by using another neural network the model can generate a vector that doesn’t have to follow the training data distribution and can reduce the correlation between features.
The Mapping Network consists of 8 fully connected layers and its output w is of the same size as the input layer (512×1).
The generator with the Mapping Network (in addition to the ProGAN synthesis network)
The AdaIN (Adaptive Instance Normalization) module transfers the encoded information w, created by the Mapping Network, into the generated image. The module is added to each resolution level of the Synthesis Network and defines the visual expression of the features in that level:

Most models, and ProGAN among them, use the random input to create the initial image of the generator (i.e. the input of the 4×4 level). The StyleGAN team found that the image features are controlled by w and the AdaIN, and therefore the initial input can be omitted and replaced by constant values. Though the paper doesn’t explain why it improves performance, a safe assumption is that it reduces feature entanglement – it’s easier for the network to learn only using w without relying on the entangled input vector.
There are many aspects in people’s faces that are small and can be seen as stochastic, such as freckles, exact placement of hairs, wrinkles, features which make the image more realistic and increase the variety of outputs. The common method to insert these small features into GAN images is adding random noise to the input vector. However, in many cases it’s tricky to control the noise effect due to the features entanglement phenomenon that was described above, which leads to other features of the image being affected.
The noise in StyleGAN is added in a similar way to the AdaIN mechanism – A scaled noise is added to each channel before the AdaIN module and changes a bit the visual expression of the features of the resolution level it operates on.
The StyleGAN generator uses the intermediate vector in each level of the synthesis network, which might cause the network to learn that levels are correlated. To reduce the correlation, the model randomly selects two input vectors and generates the intermediate vector w for them. It then trains some of the levels with the first and switches (in a random point) to the other to train the rest of the levels. The random switch ensures that the network won’t learn and rely on a correlation between levels.
Though it doesn’t improve the model performance on all datasets, this concept has a very interesting side effect – its ability to combine multiple images in a coherent way (as shown in the video below). The model generates two images A and B and then combines them by taking low-level features from A and the rest of the features from B.
One of the challenges in generative models is dealing with areas that are poorly represented in the training data. The generator isn’t able to learn them and create images that resemble them (and instead creates bad-looking images). To avoid generating poor images, StyleGAN truncates the intermediate vector w, forcing it to stay close to the “average” intermediate vector.
After training the model, an “average” wavg is produced by selecting many random inputs; generating their intermediate vectors with the mapping network; and calculating the mean of these vectors. When generating new images, instead of using Mapping Network output directly, w is transformed into wnew=wavg+𝞧(w – wavg), where the value of 𝞧 defines how far the image can be from the “average” image (and how diverse the output can be). Interestingly, by using a different 𝞧 for each level, before the affine transformation block, the model can control how far from average each set of features is, as shown in the video below.
Additional improvement of StyleGAN upon ProGAN was updating several network hyperparameters, such as training duration and loss function, and replacing the up/downscaling from nearest neighbors to bilinear sampling. Though this step is significant for the model performance, it’s less innovative and therefore won’t be described here in detail (Appendix C in the paper).

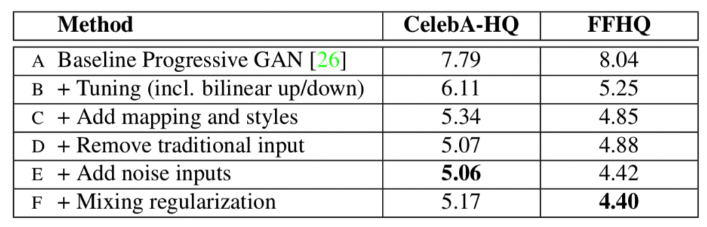
The paper presents state-of-the-art results on two datasets – CelebA-HQ, which consists of images of celebrities, and a new dataset Flickr-Faces-HQ (FFHQ), which consists of images of “regular” people and is more diversified. The chart below shows the Frèchet inception distance (FID) score of different configurations of the model.
In addition to these results, the paper shows that the model isn’t tailored only to faces by presenting its results on two other datasets of bedroom images and car images.
In order to make the discussion regarding feature separation more quantitative, the paper presents two novel ways to measure feature disentanglement:
By comparing these metrics for the input vector z and the intermediate vector w, the authors show that features in w are significantly more separable. These metrics also show the benefit of selecting 8 layers in the Mapping Network in comparison to 1 or 2 layers.
StyleGAN was trained on the CelebA-HQ and FFHQ datasets for one week using 8 Tesla V100 GPUs. It is implemented in TensorFlow and can be found here.
StyleGAN is a groundbreaking paper that not only produces high-quality and realistic images but also allows for superior control and understanding of generated images, making it even easier than before to generate believable fake images. The techniques presented in StyleGAN, especially the Mapping Network and the Adaptive Normalization (AdaIN), will likely be the basis for many future innovations in GANs.
Debating in class or composing a persuasive paper is a fruitful intellectual practice. Doing so, participants and writers are expected...
Read More
Most students wonder whether it is possible to cite an article in an essay. The answer is “Yes”! Why not...
Read More
Let us explain what is what and how it can be used. An anthology is a published collection of poems...
Read More
